
ユーザー疑問の構造化に関する研究について
ユーザー疑問の構造化に関する研究は、FAQの使いにくさを改善し「誰にでもわかりやすいFAQ」の構築モデルを、学術的理論に基づいたメソドロジーとして確立することを目的としています。
私たちは、「誰にでもわかりやすいFAQ」の定義のひとつを、ユーザーが検索時に用いるさまざまな言葉を判別し、正しい回答を表示することと考えています。同じ意図でも、ユーザーによって用いる言葉は異なります。正しい回答を表示するためには、同じ意図としてさまざまな言葉が利用される前提で、FAQを構築する必要があるのです。
そこで私たちは、ユーザーの言葉が数多く集まるコンタクトセンターの応対ログから言葉を抽出し、同じ意図ごとに分類するため、コンピュータを用いようとしました。第1回「人の言葉をコンピュータは理解できるのか」でご紹介した、人工知能にグラウンディング(言葉や文に、「意味」をヒモづけること)をさせる試みです。ただし、これは簡単なことではありません。
そのため、コンピュータを活用する準備として、人間の言葉を理解する時にどのようなプロセスを経ているかをあらためて考え、同じ意図を持つユーザーのさまざまな言葉をどのように分類するかを定義づけることにしました。
今回は、その定義プロセスについてご紹介します。
コンピュータに言語を理解させる旅の最初の一里塚:
「ダイアログアクト(※1)」
言語学には、話者の意図に基づき言葉を分析する「ダイアログアクト」と呼ばれる手法があります。
ダイアログアクトとは、他者との対話において自分の意図を伝えるためにどのような言葉を相手に伝えるのが適切であるかを考えることです。つまり、相手の考えを引き出すためにどのような質問をして、回答のどこをピックアップして、それをどう解釈すればいいのかを考えて会話をすることであり、コンタクトセンターのオペレーターが、日々の業務のなかで行っていることであるとも言えます。
私たちは、コンタクトセンターのオペレーターに対してユーザーが発する言葉のうち、問題を解決するために用いられたと考えられる言葉を、ダイアログアクトの手法を用いて「疑問」とし、それ以外の言葉(挨拶、相槌、意見、要望、苦情など)を「非疑問」として、大きく2つに分類しました。
※1.ダイアログアクト:人同士の対話において、それぞれの発話の意図がどのようなものなのかを表したもの。
例)こんにちは→「挨拶」、操作方法が分からない→「疑問」、この商品は良いね→「評価」 など
言葉と言葉の繋がりを構造化する:
「オントロジー(※2)」
「疑問」と「非疑問」の分類後、ユーザーの「疑問」には、どのような言葉と言葉の繋がりがあるかに着目し、自然言語処理で用いられるオントロジーの考え方によって構造化していくことを試みました。
オントロジーはただの文字列に意味を付与するための枠組みです。2つ以上の構成要素(=単語)の関係性から言葉の意味を定義するというもので、複数の単語が組み合わされて初めて、意味のある言葉をつくることができるという考え方です。
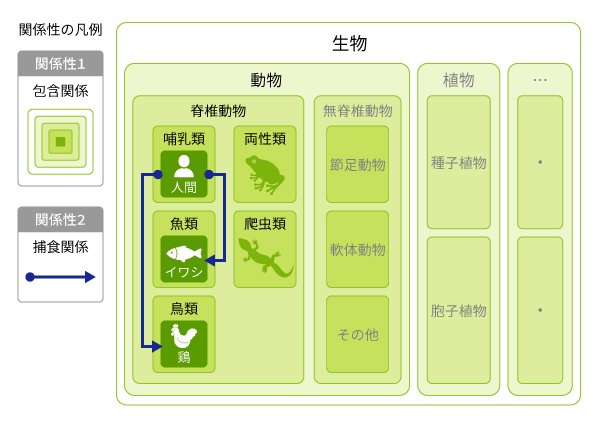
言語学におけるオントロジーは、次のような枠組みをいいます。
- 構成要素
例:「人間」「イワシ」「鶏」など - クラス
例:「生物」「植物」「動物」「脊椎動物」「哺乳類」「魚類」「鳥類」など - 関係性①包含関係
例:「動物と植物は生物である」、「脊椎動物は動物である」、「哺乳類と魚類と鳥類は脊椎動物である」、「人間は哺乳類である」など - 関係性②捕食関係
例:「人間はイワシと鶏を食べる」
※2.オントロジー:人が言葉の意味を理解する事をコンピュータで実現するため、言葉の意味を定義する概念や枠組み。言葉と言葉の意味の繋がり(関係性)を定義する。例)「日本」「東京」の繋がり(関係性)は「首都」 など
オントロジーから着想したユーザー疑問の分類
コンピュータを使って、ユーザーの疑問を分類するためには、「疑問」の重なりが無いよう定義する必要がありました。「疑問」の重なりとは、同じような「疑問」が複数存在するケースです。「疑問」の重なりがあると、コンピュータがユーザーの意図と異なる「疑問」として解釈する可能性があるためです。そこで私たちはオントロジーの考え方である「2つ以上の構成要素(=単語)が互いにどのような関係にあるか」を応用し、「サービス・商品・機能」(目的語)と、「ユーザーアクション(プロセス)」(述語)の2軸で分類する手法を作りました。
この手法によって、ユーザーの意図を導き出すことができます。 また、マトリクスの各セルに複数の「疑問の類型」を見出せます。下図のユーザー疑問のマトリクスをご覧ください。
ユーザー疑問のマトリクス
縦軸の「サービス・商品・機能」と横軸の「ユーザーアクション」の2軸の単語で、表現したい言葉を生み出します。例えば、「商品A」と「変更」と「したい」の組み合わせで「商品Aを変更したい」という言葉ができます。
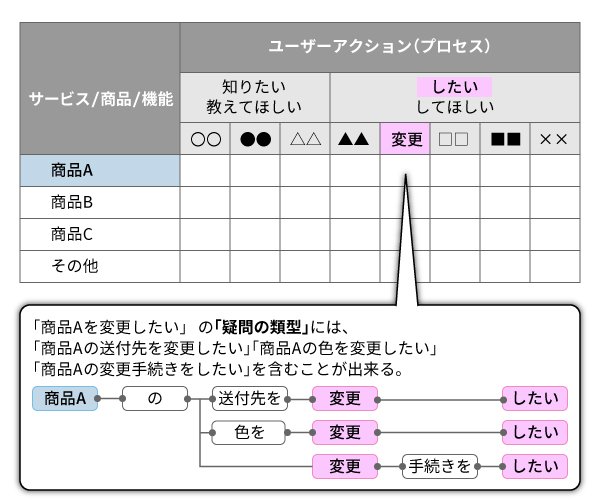
この「サービス・商品・機能」と「ユーザーアクション」の2軸の組み合わせによって、MECEな(=網羅できていて重複がない)「疑問の分類」ができました。
この度行った「オントロジーから着想したユーザー疑問の分類」について、国立情報学研究所・相澤彰子教授に見解を伺いました。
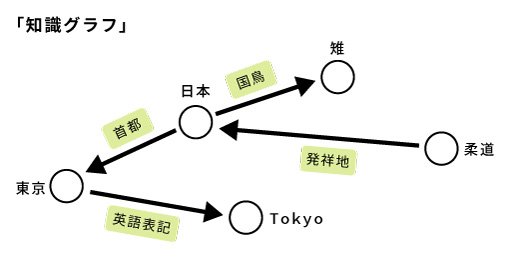
知識を表現するために広く使われているデータ構造として、RDF(Resource Description Framework)があります。RDFは「主語、述語、目的語」の3つ組(トリプル)を基本とするもので、たとえば「日本の首都は東京である」ことを、{日本(=主語)、首都(=述語)、東京(=目的語)}で表現します(注:RDFの場合、「首都」は日本と東京の関係性を表すので「述語」と呼ばれます)。また、トリプルの各要素には、オントロジー上のクラスを対応づけることができます。たとえば「日本」は「国(=クラス)」の構成要素であるなどです。
トリプルの数は膨大です。「日本の国鳥は雉である」、「柔道の発祥地は日本である」、「東京の英語表記はTokyoである」など、さまざまな関係性を記述することができます。これらのトリプルが織りなす巨大な知識のネットワークを「知識グラフ」と呼びます(図)。自然言語文を知識グラフに対応付けること(注:前回のコモン・グラウンディング)は、言語の意味を客観的に捉えるための有効な手段です。
さて、今回の取り組みについて考えてみましょう。ここで扱うユーザーの疑問では、主語は必ずユーザー自身なので、トリプルを作るためには「目的語」と「述語」を決めればよいことになります。たとえば「期限が切れる日」を「知りたい」などです。これは、ユーザーの疑問を知識グラフに対応付ける作業です。さらに、これらの疑問を体系づけて「期限が切れる日」を「有効期間」の要素とみなしたり、「知りたい」と「教えて欲しい」をグループ化したりすることで、疑問の階層を得ることができます。このような階層化は、ドメイン(※3)オントロジーの構築作業とみることができます。
今回のように、実際に収集したユーザーの発話を現場の担当者の意見も聞きながら丁寧に分析して類型化して行くボトムアップな方法は、まさにドメインオントロジーの構築に必須のアプローチといえるでしょう。また、このような手法を確立することで、サービスやニーズの変化を素早く捉えて柔軟にオントロジーに反映することが可能になります。言語からオントロジーへのマッピングに必要となる辞書や正解事例などをオントロジーと同時に収集できることも、ボトムアップ的なオントロジー構築の強みです。RDFで表現された知識グラフは人間にとって決して可読性が高いものではありませんが、マトリックス表現は人間に理解しやすいというメリットもあります。
オントロジーの構築は、いま進行中のDX(デジタルトランスフォーメーション)においても中心的な課題です。MECEなFAQの実現に向けて、より多くのドメインで検証を進めて行けるとよいと思います。
※3.ドメイン:ここでのドメインとは、業種・業界や特定の範囲を指す。
今回、ダイアログアクトとオントロジーの考え方を用いて、
同じ意図を持つユーザーのさまざまな言葉を分類するための定義ができました。
- ダイアログアクト:「疑問」「非疑問」の2つに分類
- オントロジー:「疑問」の内訳となる、重なりのない「疑問」の分類
この分類の定義をコンピュータに理解させるために、私たちがどのように実装をおこなったか、次回は機械学習(※4)と分類器(※5)を用いた分類の自動化についてご紹介します。ご期待ください!
※4.機械学習:人が行う特定の判断をコンピュータで実現するため、コンピュータに学習させること。主に人が判断した正しいデータ(教師データ)を投入してコンピュータが学習する。
※5.分類器:機械学習によって学習されたコンピュータのこと。学習された状態に基づき、未知のテキストデータを複数のカテゴリに自動で分類する。
研究者

相澤彰子 氏
国立情報学研究所:コンテンツ科学研究系教授
専門分野:自然言語処理・情報検索
研究紹介
言語テキストから"知"を生み出す
人間にとって、言葉は不可欠な道具です。たがいに意思を伝え合うコミュニケーションの手段として、また記録を伝えるためにも必要です。逆にいえば、言葉の使われ方を解析すると人間の活動を垣間見ることができます。私の興味は、実にその点にあります。
言語は人間の知的な活動の基盤であり、コンピュータによる言語処理は、知能システムの欠かせない構成要素となっています。言語処理により人間の情報収集・発信や意思決定を支援するためには、単にコンピュータでテキストの意味を解析するだけではなく、テキストの読み手・書き手である人間が、どのように言語を処理しているかを想定して、システムを構築する必要があります。本研究では、深層学習を含む機械学習、コーパス分析、アノテーションなどを用いて、コンピュータによるテキストの意味解析と人の言語活動のモデル化、および両者をつなぐ手法の開発に取り組んでいます。
ご意見・アドバイス
- 「モノ・コト」の構造化はオントロジーと呼ばれる学術領域があるが、ゼロからオントロジーを構築するのは非常にコストがかかる
- 今回の取り組みでは、オントロジーの概念を活用し、ラベルやタグ、アノテーションの組み合わせで実現できるかもしれない
- 言葉と言葉の繋がりの研究は自分の経験が活かせる領域であり、構築している分析資産を活かせる可能性も高い
担当者

野原耕介
SCSKサービスウェア株式会社
第四事業本部 事業推進部 事業推進課
経歴
関西圏の大手企業に向けてBPOやコンテンツソリューションサービスの拡販に従事
「ユーザー疑問の構造化研究」に参画
音声認識データの活用やテキストデータの自動分類など「疑問の構造化」メソドロジーの改良を担当
本取り組みに向けた抱負
本研究の領域は壮大で、さまざまなサブテーマを含んでいる。たとえば疑問の定義やテキストデータの自動分類などであり、これらに課題を抱えている企業も多いと認識している。
本研究のメインテーマの完遂に加えて、これらサブテーマに対しても学術理論と当社が永年培ってきたノウハウを融合させ、企業やエンドユーザーへの価値提供につなげていきたい。

