
ユーザー疑問の構造化に関する研究について
ユーザー疑問の構造化に関する研究は、FAQの使いにくさを改善し「誰にでもわかりやすいFAQ」の構築モデルを、学術的理論に基づいたメソドロジーとして確立することを目的としています。
私たちは、「誰にでもわかりやすいFAQ」における定義のひとつとして、ユーザーが検索時に用いる様々な言葉を判別し、正しい回答が表示されることと考えています。同じ意図でも、ユーザーによって用いる言葉(言い回し)は異なります。ユーザーが求めている正しい回答を表示するためには、同じ意図でも様々な言葉が利用されていることを前提として、FAQを構築する必要があるのです。
最終回となる今回は、機械が人の言葉の意図を理解する方法をご紹介します。
実務における課題
機械が人の言葉の意図を理解するには機械学習など学術のアプローチがあり、あらかじめ機械が「人の言葉の意図と言い回し(学習データ)」を学習していれば、機械が人の言葉の意図を汲み取った対応ができます。(第1回「人の言葉をコンピュータは理解できるのか」)
しかし、理論的に可能であっても、機械が人の言葉の意図と言い回しを学習するには学習データを作成する課題があります。
たとえばコンタクトセンターには、「機械に人の言葉の意図を理解させる」取り組みのひとつにチャットボット運用があります。一般的なチャットボットの学習手順は以下の通りです。
【一般的なチャットボットの学習手順】
①コンタクトセンターの対応ログから、カテゴリーごとの問い合わせ傾向を可視化
②問い合わせ量が多く、自己解決可能なカテゴリーを選定
③選定したカテゴリーに該当するQA(質問文と回答文のセット)を作成
④QAに同義で別の言い回し文を適宜付加
⑤QAおよび言い回しのデータセットをチャットボットに登録
ところが、この手順には主に以下の落とし穴がありました。
【チャットボットの学習の落とし穴】
①コンタクトセンターのカテゴリー構造と、チャットボットQAのカテゴリー構造が異なる。
②オペレーターによってカテゴリーの付け方(学習データの品質)にバラつきがある。
③QA別の言い回し文の案・パターン数に基準が無く、属人的な運用になる。
これらを踏まえると、実務で機械が人の言葉の意図と言い回しを学習するには、大量かつ正確な学習データ(人の言葉の意図と言い回しのセット)を新規作成する必要があります。実現するためには膨大な人的リソースやノウハウが必要でした。
課題に対するアプローチ
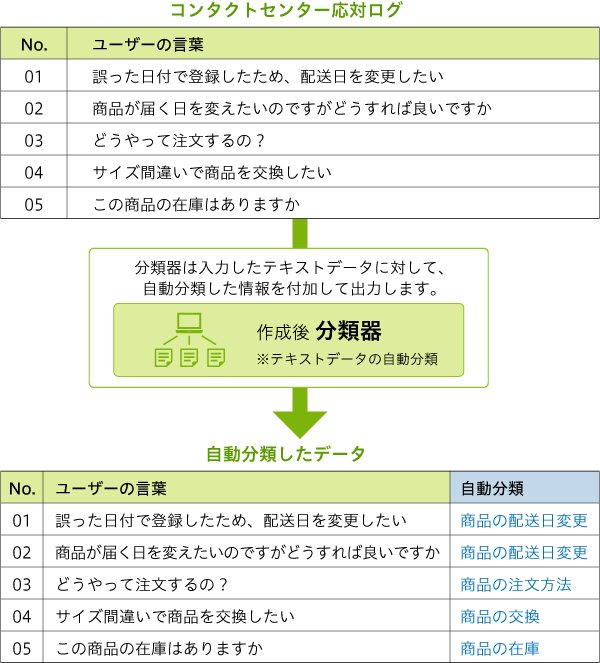
大量かつ正確な学習データを効率的に作成するため、当社では機械学習を活用した分類器を作成し、大量のユーザー発話データ(チャットログや音声認識テキスト)に対して、あらかじめ定義した言葉の意図のラベルを自動付加しました。
分類器の作成には相澤先生から助言をいただき、サポートベクターマシン(以下SVM)という機械学習の手法を採用しました。
SVMとは数学的に言うと「教師データを用いて、多次元空間上の有限個の点を要素とする2つの集合A・Bを最も効率的に分離する超曲面を計算で求めるアルゴリズム」です。簡単にいうと少数の分類のお手本(教師データ)から、分類のパターンを定義し、未知のデータを自動で判別するアルゴリズムです。他のアルゴリズムと比較して、少ないデータ量でも高い性能を発揮することが特徴です。
分類ラベルの定義には、第2回(第2回「そもそも我々は人間の言葉をどのように理解しているのだろうか」)でご紹介した「ユーザー疑問のマトリックス」を活用しました。この分類ラベルは、MECEかつラベルの粒度のバラつきが小さい構造で、様々なチャネルに対して共通に活用できる特徴があります。
機械学習を用いたテキスト分類について、国立情報学研究所・相澤彰子教授に見解を伺いました。
自然言語で書かれた文章を自動的に分類する問題は「テキスト分類」と呼ばれ、自然言語処理の様々な場面で登場します。その基本となるのは、どのようなカテゴリーに分類したいのかを決める「分類ラベル」と、どのように文章を分類したいかを決める「教師データ」です。
たとえばツイートを正負の感情に分ける場合には、「ポジティブ」、「ネガティブ」、「ニュートラル」が分類ラベル、いくつかのツイートを選んで人手でラベルを対応づけたものが教師データとなります。
テキスト分類は機械学習の典型的な分類問題なので、苦労してソフトウェア開発をしなくても、公開されている多くの優れたプログラムを利用することが可能です。しかしながら、教師データについては問題に応じて自分で作成する必要があります。つまり教師データを作ることがテキスト分類の最も重要な開発工程となります。教師データは人間が納得できるものでなければならないのはもちろんですが、コンピューターにとっても合理的なものである必要があります。教師データの構築は、ドメインの知識を体系づけ、コンピューターで処理ができるように整える作業といえます。
教師データは十分な量を準備するにこしたことはありませんが、現実にはその作業には手間がかかります。そこで、少数の教師データでうまく学習をさせるための様々な工夫が提案されています。たとえば、いったん分類器を学習させて、それを新たなデータに適用し、得られた結果を疑似ラベルとしてさらに学習に使うこともよく行われます。半教師付き学習や遠距離教師付き学習(distant supervision)と呼ばれる手法です。また、すでにある教師データを書き換えて、もとの訓練データに追加する、データ拡張と呼ばれる手法もあります。この書き換えは必ずしも高度なものではなく、たとえば文章から1文字を削除することで、ノイズに強い分類器を作るなどの単純な方法もよく用いられます。
さらに、人間の判断にも揺れや誤りが含まれます。このため、教師データの作成では、わかりやすい作業ガイドラインを準備したり、複数の作業者によるラベルの一致度を確認したりといった品質管理も重要になります。近年では、教師データ作成における人間側のバイアスや確信度も分類器の性能向上に向けた重要な手がかりであるとされ、研究対象となっています。
分類器を構築するにあたり、相澤先生の助言をもとに以下の工夫を施しました。
- 分類器は一から自作せず、公開済のPythonライブラリ※の組み合わせにより、効率的に構築。
- 分類器の性能をコンフュージョンマトリックス(混同行列)やラーニングカーブ(学習曲線)などPythonライブラリで可視化し、効率的にチューニングを実施。
- 分類器に必要な教師データの品質管理には、作業者によってラベルの付け方にブレが生じないよう、アノテーションガイドラインの定義、一致度の検定(κ係数)、カリブレーションを実施。
これらにより、分類器のアウトプットとして、「ユーザーの生の発話と分類ラベル(意図)」のデータセットを大量に獲得しました。
※Pythonライブラリ:機械学習やデータ可視化、データ加工など目的別に、便利な関数や機能をまとめたもの。プログラム構築作業が効率化される利点がある
検証方法と結果
当社の既存プロジェクトにおいて、「ユーザーの生の発話と分類ラベル(意図)」のデータセットをチャットボットに登録して、チャットボットの正答率を観測しました。手順は次の通りです。
①「ユーザーの生の発話と分類ラベル(意図)」のデータセットを、チャットボットQAに紐づけて登録。
- 分類ラベル(意図):チャットボットQAの代表質問(Q)に登録
- ユーザーの生の発話:チャットボットQAの言い回し文(Q)に登録
②チャットボットの正答率の観測
「ユーザーの生の発話と分類ラベル(意図)」のデータセットをチャットボットに追加登録した前後6か月間のチャットボットの正答率を観測。※正答率とはユーザーからの質問回数(母数)に対して妥当な回答をした回数(子数)。
本検証でチャットボット正答率を測定した結果、学習前3か月間の平均正答率が約61.7%、学習後3か月の平均正答率が約70.5%となり、平均正答率が8.8ポイント向上しました。
つまり、当社のユーザー疑問の構造化メソッドにより、チャットボットの性能を向上できることを実証できました。
具体的には以下のような質問に対しても回答できるようになりました。
【アパレルECの例】
・ユーザーの発話 「不良品だった場合の問い合わせ先を知りたい」
チャットボットの回答 「返品手続きはこちらです」
・ユーザーの発話 「服の色が思っていた感じと違った」
チャットボットの回答 「返品手続きはこちらです」
結論として、(従来と比較して)機械が人間の様々な言葉の意図を理解して対応できるようになりました。
ユーザー疑問の構造化に関する研究の成果
今回の研究により、私たちは「機械が人間の様々な言葉の意図を理解」するため、オントロジーによるアプローチを当社独自のメソドロジーとして得ることができました。
このメソドロジーを構成する要素は、以下の3点です。
- SVMを活用した「テキストデータの自動分類器」
- チャネル共通で活用できる「発話の分類定義メソッド(ユーザー疑問のマトリックス)」
- 正確な教師データを作成する「アノテーションメソッド(ガイドライン・検定・カリブレーション)」
そして、今回の研究は、以下のような価値に繋がると考えています。
- チャットボットによるユーザーの自己解決率の向上
- チャットボット運用における効率化および属人化解消
- FAQ初期構築の効率化および納期の短縮
今後は、研究成果であるメソドロジーの改良に取り組んで参ります。
具体的には、テキストデータの自動分類において、深層学習(ディープラーニング)を活用し、分類精度や学習効率の向上に繋げたいと考えています。
全3回の研究報告は、「第1回 人の言葉をコンピュータは理解できるのか」「第2回 そもそも我々は人間の言葉をどのように理解しているのだろうか」、そして今回の「第3回 機械が人の言葉の“意図”を理解する方法」で最後となります。
ここまで読み進めていただき、ありがとうございました!
研究者

相澤彰子 氏
国立情報学研究所:コンテンツ科学研究系教授
専門分野:自然言語処理・情報検索
研究紹介
言語テキストから"知"を生み出す
人間にとって、言葉は不可欠な道具です。たがいに意思を伝え合うコミュニケーションの手段として、また記録を伝えるためにも必要です。逆にいえば、言葉の使われ方を解析すると人間の活動を垣間見ることができます。私の興味は、実にその点にあります。
言語は人間の知的な活動の基盤であり、コンピュータによる言語処理は、知能システムの欠かせない構成要素となっています。言語処理により人間の情報収集・発信や意思決定を支援するためには、単にコンピュータでテキストの意味を解析するだけではなく、テキストの読み手・書き手である人間が、どのように言語を処理しているかを想定して、システムを構築する必要があります。私たちの研究では、深層学習を含む機械学習、コーパス分析、アノテーションなどを用いて、コンピュータによるテキストの意味解析と人の言語活動のモデル化、および両者をつなぐ手法の開発に取り組んでいます。
ご意見・アドバイス
- 「モノ・コト」の構造化はオントロジーと呼ばれる学術領域があるが、ゼロからオントロジーを構築するのは非常にコストがかかる
- 今回の取り組みでは、知識を構造化するオントロジーの考え方を活用し、ラベルやタグ、アノテーションの組み合わせで実現できるかもしれない
- 言葉と言葉の繋がりの研究は自分の経験が活かせる領域であり、構築している分析資産を活かせる可能性も高い
担当者

三樹 宏太
SCSKサービスウェア株式会社
デジタルサービス推進部 副統括
経歴
主に流通サービス系企業向け営業に従事
流通サービスの新規業務委託案件の案件醸成および案件獲得業務に従事
流通サービス・金融・情報通信を中心としたセンター運営に従事
チャットボットシステムの調査・検証・販売支援、流通サービス・金融における導入支援業務に従事
本取り組みの総括
この度は、私たちの取り組みを最後までご覧いただき、誠にありがとうございました。
ユーザーにとって本当にわかりやすいFAQとはどういったものかというテーマを掲げて、相澤先生にご協力・ご指導をいただきました。
これまでは、当社の経験則で構築・メンテナンスを行ってきたFAQを、相澤先生の学術的な見解や示唆を基に新たに整理し直し、構造化することを試みてまいりました。
この試みを実施していく上では、特定の経験者に依存することや現場管理者の負荷が増加しないようにしつつ、再現性の強化と構築の省力化を両立させることにも挑戦しました。
この結果は本文に記載の通りで、ユーザーにとってわかりやすいFAQを構築するその一助を担うことができたのではないかと思います。
今後も研究を続けることによって、よりユーザーにとってわかりやすいFAQを構築していく取り組みを進めてまいります。
末筆ではございますが、4年間にわたって学術指導をいただきました相澤先生へ、心より御礼申し上げます。

